OCR vs LLM: How We Built Automated Invoice Scanning

Automated invoice scanning systems combine OCR for raw text extraction with LLMs for contextual reasoning, field mapping, and business logic. A two-stage LLM pipeline handles raw extraction first, then categorization and enrichment. RaftLabs built a production system using Gemini 2.5 Flash that processes thousands of vendor invoices at 97% line-item accuracy, cutting compute costs 70% compared to Claude. The hybrid approach handles variable layouts, handwritten notes, and messy scans that traditional OCR cannot process reliably.
Key Takeaways
- Standard OCR fails on real-world invoices because vendor layouts vary wildly. One vendor labels the total "Amount Due" in the header, another calls it "Grand Total" in the footer. OCR can't reason about that. LLMs can.
- Combining OCR for text extraction with LLMs for contextual reasoning lifted line-item accuracy from 88% to 97% in RaftLabs' production system.
- A two-stage LLM pipeline works better than a single call. Stage 1 extracts raw fields into schema-perfect JSON. Stage 2 applies business logic, validates UPCs, and maps product categories. Keeping these separate reduced latency and improved accuracy.
- Prompt engineering is not optional. Explicit instructions like "preserve original line-item order" had measurable impact on output quality. Treat prompts as production code.
- Gemini 2.5 Flash reduced per-document compute cost by 70% versus Claude at comparable quality, making the economics work for high-volume processing.
About a year ago, we hit a wall with invoice processing.
The automation pipelines we had built for FMCG, healthcare, and logistics worked beautifully, but invoices were a whole different beast.
Standard OCR tools did well with OCR invoice scanning, turning pixels into text. But when it came to mapping that text into structured, reliable outputs for finance systems, they fell short. We kept running into partial extractions, missing fields, and malformed JSON outputs.
It’s estimated that 80–90% of the world’s data is unstructured, with text files and documents making up a big chunk of it. Invoices are a perfect example of this chaos.
Producing clean, schema-perfect data for downstream automation needed more than just text recognition. It required adaptability and contextual reasoning across unpredictable document formats.
Each vendor uses a different layout, with formats and terminology that vary wildly across industries. Totals might appear in headers, footers, or hidden deep in tables.
Then there are smudged scans, odd fonts, and delivery charges mixed with line items. It didn’t take long for us to see why traditional systems built on regexes and static templates struggled to keep up.
That’s when we started thinking: what if we let AI handle the “understanding” part?
Over the past year, we rebuilt our client’s invoice processing system using Large Language Models (LLMs). We started with Claude, experimented rapidly, and finally moved to Google’s Gemini 2.5 Flash.
The result is a production-grade workflow that ingests multi-page invoices, adapts to vendor-specific formats, and delivers schema-perfect JSON for invoice data extraction. Accuracy jumped to 97%, and compute costs dropped by 70%.
This post covers: the problem we ran into, why OCR alone isn’t enough for invoices, how we combined LLMs with classic OCR, and what actually worked in production. Useful for tech teams scaling invoice automation and anyone evaluating LLM extraction workflows.
For us, this project reinforced something we’ve seen across multiple builds: clean, modular engineering paired with the right AI models can turn complex ideas into production-ready systems faster than you might expect.
This project is another example of that mindset at work.
The Challenge: Tackling Real-World Invoice Variability
For one of our SaaS startup clients, we were solving a critical problem: enabling AI to manage inventory at scale.
The platform helps gas stations and convenience stores automate their inventory workflows, eliminating hours of manual invoice data entry and providing real-time visibility into product availability across locations.
The core challenge was handling the sheer variability in invoices. They came in all forms like computer-generated PDFs, handwritten paper notes, and semi-structured formats.
On top of that, the quality of these invoices was far from reliable. Many were poorly scanned, crumpled, or so faded that even humans struggled to read them.
This variability made it clear that a standard OCR system on its own would never deliver the accuracy and resilience we needed for production-grade performance.
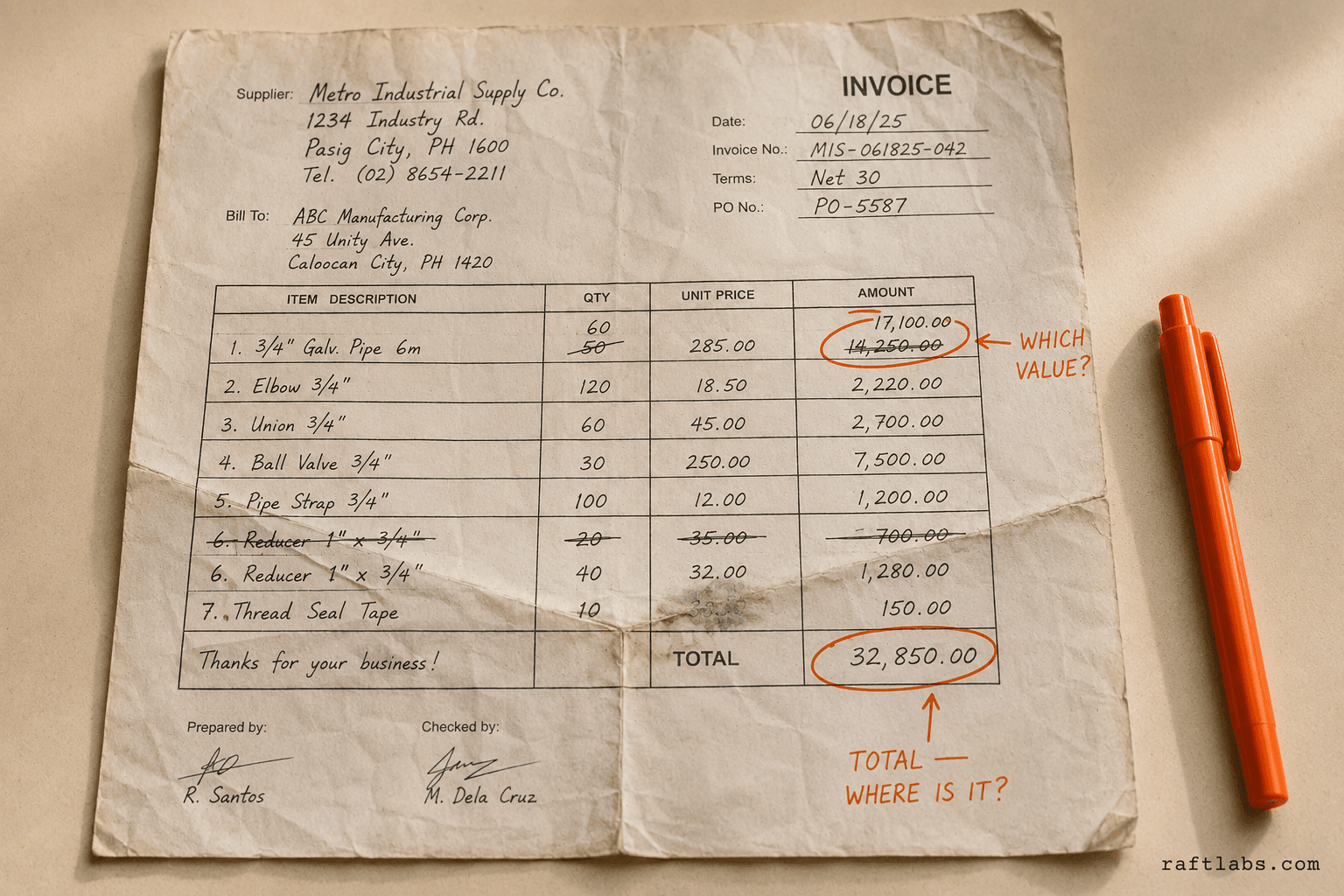
What Is Automated Invoice Scanning (and Why OCR Alone Doesn’t Cut It)

If you’ve ever built or used an invoice processing tool, you know the drill: scan a PDF, run OCR, parse the text, and pray the fields map correctly.
On paper, it sounds simple. In reality, invoices are a chaotic mix of:
Fixed fields (like invoice numbers and dates).
Semi-structured tables (line items, quantities, taxes).
Free-form notes and disclaimers scattered across pages.
OCR (Optical Character Recognition) is great at the first step, turning pixels into text. But once you ask it to understand the text or extract relationships (like matching vendors to line items), it falls short.
| OCR Strength | OCR Limitation |
|---|---|
| Converts pixels to text | Lacks semantic understanding |
| Works well with fixed templates | Breaks when layouts vary |
| Fast and inexpensive | Struggles with skewed/noisy scans |
We ran into all these problems while processing thousands of vendor invoices. One vendor’s total was labeled “Amount Due” in the header, another called it “Grand Total” in the footer. Some embedded line items neatly in tables, while others hid them within paragraph text.
This is where Large Language Models (LLMs) came in. Unlike OCR, they don’t just read the text, they reason about it. McKinsey’s 2024 State of AI report found that document processing and data extraction are among the top 3 use cases where generative AI is delivering measurable ROI in production environments.
Here’s how LLMs elevated our invoice scanning workflow:
1. Structured Data Extraction
They map raw text to rich JSON schemas: invoice_number, vendor_address, even nested arrays for line items.
2. Layout Flexibility
Whether the total is in the header or footer, LLMs can infer its meaning from context.
3. Imperfection Tolerance
Smudged or skewed scans? An LLM can deduce “₹12,599.00” from “₹12,59?.00” using surrounding cues.
4. Business Logic
Need to exclude delivery fees or flag alcohol content?
You can encode these rules directly in prompts, no need for brittle template matching.
So, by combining OCR for raw text and LLMs for reasoning, you get the best of both worlds: speed at the pixel layer, intelligence at the data layer.
Check out: Our Generative AI Development Services
Key Differences Between OCR and LLM for Invoice Scanning
When you’re trying to automate invoice data extraction, OCR and LLMs do very different jobs. Knowing where each one fits helps you build a system that works at scale.
| Feature | OCR Only | LLM (with OCR Input) |
|---|---|---|
| Text Extraction | Yes | Relies on OCR output |
| Contextual Reasoning | No | Yes |
| Handles Layout Changes | Poorly | Reliably |
| Output Format | Unstructured text | Structured (e.g., JSON) |
| Error Tolerance | Low | High |
| Business Logic | Hardcoded, inflexible | Prompt-driven, highly flexible |
| Best Use Case | Simple, uniform documents | Complex, variable invoices |
1. Core Functionality
OCR pulls text out of scanned PDFs or images. It’s quick and works well for basic text recognition. But it has no idea what the text means or how things connect.
LLMs pick up from there. They understand the text, figure out relationships, and turn it into structured data. But they can’t work without OCR or digital text as input and need more compute power.
-
Handling document variability: OCR is fine for clean, fixed-layout documents. Messy scans, unusual formats, or varied vendor styles cause it to struggle. LLMs handle variety better. They infer field meanings from context and work even when layouts shift or scans aren’t perfect.
-
Data structuring and output: OCR gives you plain text. You need extra rules (regex) to map fields, which break when formats change. LLMs output structured data like JSON directly, linking line items to totals and respecting the expected format.
-
Dealing with imperfections: a smudge, skewed scan, or uncommon font can throw off OCR. LLMs use context to infer missing or unclear values, which improves accuracy on real-world documents.
-
Business logic and customization: OCR stops at pulling text. Business logic has to be hardcoded separately, and it’s brittle. LLMs let you embed logic directly in prompts, like excluding certain charges or mapping product categories, which makes the system easier to update.
-
Scalability and cost: for simple jobs, OCR is faster and cheaper. LLMs cost more per call but paired with OCR they reduce manual work and scale better for complex, variable documents.
OCR is great for pulling text fast, but it hits a wall with complex invoices and messy layouts. LLMs bring the brains, understanding context, cleaning up errors, and structuring data. Combine both, and you get a system that’s faster, smarter, and ready to scale.
Comparison of Custom LLM vs Off-the-Shelf Tools vs DIY OCR
| Feature | Custom LLM | Off-the-Shelf Tools | DIY OCR |
|---|---|---|---|
| What it means | OCR + LLM for understanding & structuring | Ready-made OCR & document AI platforms | Open-source or self-built OCR pipeline |
| Setup Effort | Medium (custom setup needed) | Low (plug & play) | High (you build everything) |
| Cost | Medium to High (API + infra) | Medium to High (subscriptions) | Low (mostly free) |
| Accuracy | Best for complex & messy docs | Good for standard docs | Good for clean docs |
| Handles Different Layouts | Excellent | Limited | Poor |
| Structured Data Output | Fully automated (JSON, fields) | Partial | Manual (regex, rules) |
| Business Logic Support | Yes (prompt-based logic) | Limited | No |
| Customization Level | High effort | Low to Medium | Very High |
| Scalability | High | Medium | Low |
| Maintenance Over Time | Low to Medium | Medium | High |
| Risk of Format Breakage | Low | Medium | High |
| Best For | Production-grade automation | Quick MVPs | Simple, fixed formats |
How an Automated Invoice Scanning System Works
Automating invoice processing is a step-by-step pipeline that takes raw invoices and turns them into clean, structured data ready for your systems.
Here’s how the workflow looks:

- Collecting Invoice Samples
- Pre-processing Invoices
- Applying OCR (Baseline Approach)
- Adding LLMs for Smarter Parsing
- Validating and Storing Data
Step 1: Collecting Invoice Samples
Invoices come from everywhere, email attachments, scanned paper copies, vendor portals, or direct uploads. To make the system strong, you need samples from all these channels so it can handle different formats and layouts.
Once collected, everything goes into a secure, centralized digital repository. This makes it easier to process and also helps train and improve the model over time.
Step 2: Pre-processing Invoices
Scanned invoices are rarely perfect. They might be blurry, skewed, or low contrast. Here’s where pre-processing helps:
Fix skewed images and remove noise
Adjust brightness and contrast for clarity
Crop unnecessary parts to focus on key areas
Bad files (blurry, incomplete, or corrupted) get flagged for manual review or rescanning to avoid errors later.
Step 3: Applying OCR (Baseline Approach)
OCR (Optical Character Recognition) pulls out text from the cleaned-up invoice images. It works well for standard, clear documents.
But there’s a catch:
It struggles with complex layouts or noisy scans.
Field mapping (like invoice number, date, or totals) often needs rigid templates or regex rules, which break if formats change.
For simple jobs, OCR is fine. For anything tricky, you’ll need more.
Step 4: Adding LLMs for Smarter Parsing
This is where Large Language Models (LLMs) step in and make the system smarter.
They take the OCR output and understand the context.
Instead of using rigid rules, LLMs figure out relationships and adapt to new formats.
They can map the data directly to structured formats like JSON, linking line items, totals, vendors, even on multi-page or unusual invoices.
You can even embed business logic into LLM prompts (like excluding certain charges or mapping product categories). That means fewer hardcoded rules and more flexibility.
They also handle imperfections better by filling in missing or unclear values using context.
Step 5: Validating and Storing Data
After extraction, the data isn’t just dumped into your system. It’s checked carefully:
Totals are cross-verified with line items
Taxes and key fields are validated against vendor records
Anything with errors or low confidence is flagged for manual review
Once validated, the data is stored securely in financial or document management systems. From there, it’s ready to flow into your ERP or accounting platform for automated approvals and faster payments.
OCR gets you started, but pairing it with LLMs takes invoice automation to the next level. You get cleaner data, fewer manual fixes, and a system that keeps improving over time.
Performance Benchmarks: Accuracy, Latency & Cost
We kept seeing vendors claim “97% accuracy,” but without showing what that actually meant. No breakdown by document type, no clarity on latency, and definitely no cost transparency.
For our automated invoice-scanning system, we built a simple benchmark dashboard, just enough to show teams where the system performs well and where it needs more training. Here’s a representative breakdown:
| Invoice Type | Accuracy | Avg. Latency | Cost per Invoice |
|---|---|---|---|
| Retail | 98% | 1.2s | $0.03 |
| Telecom | 95% | 1.5s | $0.03 |
| Handwritten | 89% | 1.9s | $0.03 |
(These are representative values, actual numbers vary by vendor, format, and document quality.)
The automation pipelines we had built for FMCG, healthcare, and logistics worked beautifully, but invoices were a whole different beast. Every vendor, format, template, and layout behaves differently, so having this level of visibility helps teams understand where they stand without relying on vague “97% accuracy” labels.
Technical Implementation: How We Combined LLMs with Classic OCR
So how did we actually build this?
Designing a reliable pipeline for AI invoice extraction required solving two distinct challenges: converting raw OCR text into structured data and enriching that data with domain-specific intelligence.
The core idea was straightforward: let OCR handle what it does best,i.e., turning pixels into text and then delegate the more complex reasoning to an LLM. But moving from prototype to production meant tackling issues like schema consistency, latency, and compute cost.
A single LLM call wasn’t enough to handle the complexity of multi-page invoices with nested line items and diverse vendor conventions. To overcome this, we split the workflow into two focused stages.
- The first stage extracts core fields into a schema-perfect JSON, ensuring clean and consistent output.
- The second stage applies business logic, validation, and enrichment, mapping product categories, cross-checking UPCs, and embedding metadata.
This separation improved accuracy, reduced latency, and kept each model invocation purpose-built for its task.
1. Two-Stage LLM Pipeline
We designed a two-stage pipeline:
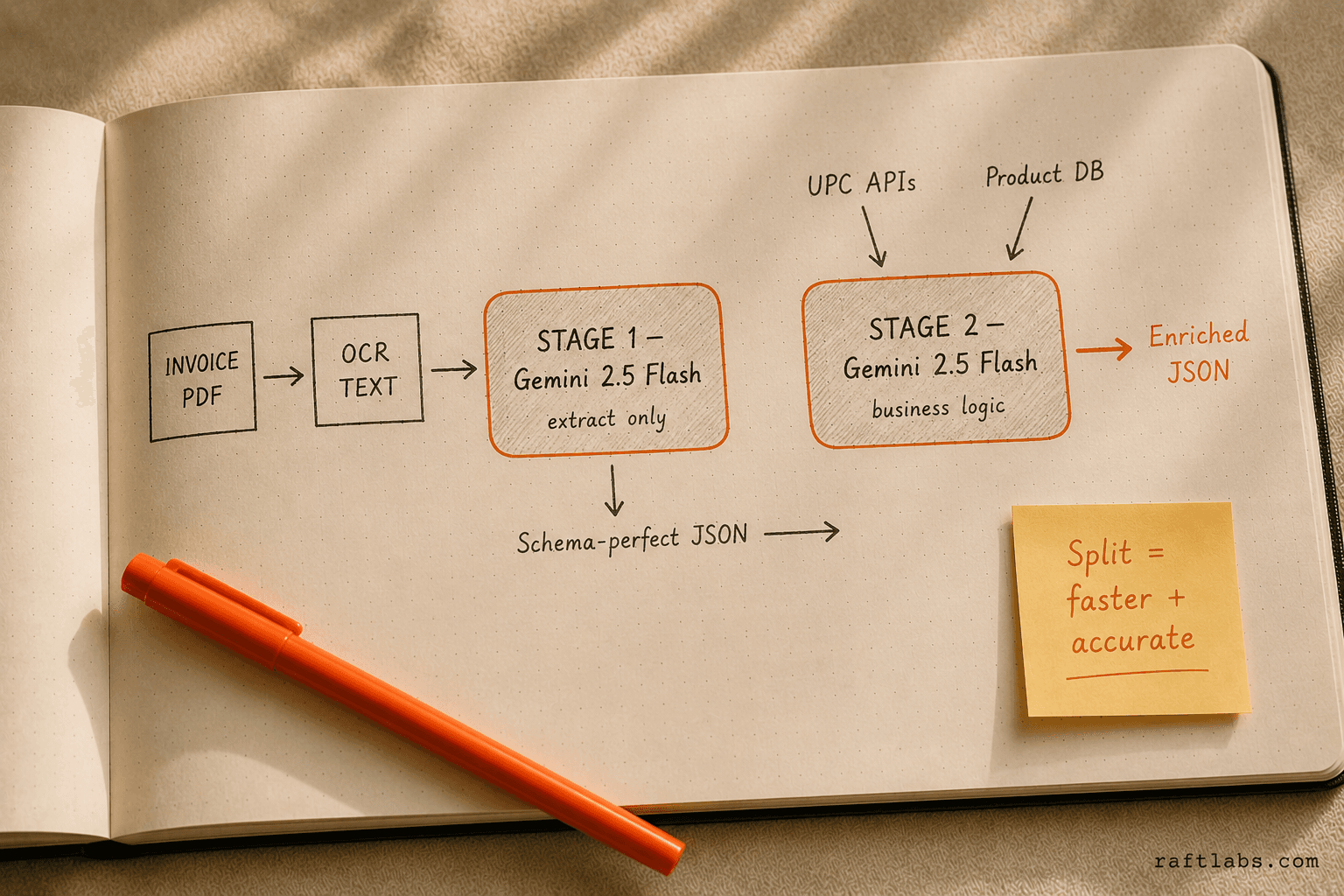
Stage 1: Raw Extraction
We used Gemini 2.5 Flash to convert raw OCR text into a structured JSON object. The model receives the PDF buffer and a strict schema (defined in Zod) to enforce consistent output.
const result = generateObject({
schema: invoiceSchema, // zod-defined JSON structure
model: 'gemini-2.5-flash',
prompt: systemPrompt,
files: [pdfBuffer]
});
Here, we ended up with a clean invoice object that had all the key details like identifiers, dates, totals, and every line item, preserved exactly in the original order.
Stage 2: Categorization & Enrichment
The second LLM call adds intelligence:
Maps ”Dove Shampoo 180 ml” to
{category: “Personal Care”, subcategory: “Hair Care”}.Flags perishability, verifies alcohol content, validates size units.
Cross-checks UPCs and pulls metadata (brand, images) from external APIs for product invoices.
This separation helped us to keep the initial extraction fast and fully schema-focused.
Once we had clean, structured data, it became much easier to layer on domain-specific rules later like mapping product categories, validating UPCs, or flagging edge cases without overloading the core extraction step.

2. Prompt Engineering Principles
In any LLM-powered workflow, prompt design often determines whether your system feels like a reliable engine or an unpredictable black box.
For automated invoice scanning, getting the prompts right was critical to ensure clean, schema-perfect outputs, reduce parsing errors, and avoid edge-case failures on messy vendor documents.
Here are some of the techniques that made our pipeline production-grade:
| Technique | Impact |
|---|---|
| Schema-Driven (Zod) | Forces well-formed JSON, reduces parsing errors. |
| Explicit Instructions | “Preserve original line-item order” improved fidelity. |
| Focused Extraction | Fuel invoices skipped taxes and delivery charges. |
| Iterative Refinement | Continuous A/B tests slashed false positives. |
Fine-tuned prompts act as the glue between raw OCR output and structured data pipelines.
In high-volume automated invoice scanning systems, even small prompt improvements can save hours of manual QA and reduce integration failures downstream.

Treating prompt engineering as a core part of the system completely changed the game for us.
It turned what started as a fragile prototype into a workflow that’s resilient and ready for production at scale.
As LLMs keep evolving, we’ve learned that pairing strong prompt strategies with strict schema validation is the key to building reliable and scalable invoice data extraction pipelines.
Check Our AI Development Services for startups and enterprises
Which LLM Performed the Best?
Building a scalable pipeline for automated invoice scanning meant we needed a model that could handle large, multi-page documents without losing context, deliver high accuracy for invoice data extraction, and still keep latency and costs low for high-volume workloads.
We first tried Claude 3.7 and 4. Their 64k token context windows were impressive and worked really well for OCR invoice scanning, especially on multi-page telecom and utility invoices. Out of the box, they supported PDF parsing and felt solid for early prototyping.
But as we moved closer to production, the high per-token cost and fragile PDF support started causing friction. It also meant adding glue code we weren’t keen on maintaining long term.
Next, we tested Gemini 2.5 Pro and Flash. Both came with comparable 65k token context lengths, which made them just as capable of processing long-form invoice data without the need for aggressive chunking.
Gemini 2.5 Pro really stood out for its extraction quality and consistency across diverse vendor layouts.
But under bulk queues, latency became an issue, making it less suitable for real-time AI invoice extraction at scale.
| Model | Pros | Cons |
|---|---|---|
| Claude 3.7 / 4 | Huge context window (64k tokens). | High cost, fragile PDF support. |
| Gemini 2.5 Pro | Strong extraction quality. | Higher latency for bulk queues. |
| Gemini 2.5 Flash | Fast, cheap, and quality matched Pro. | Slightly weaker on rare edge cases. |
In production, Gemini 2.5 Flash became the clear winner.
It delivered schema-perfect JSON reliably, enabling us to automate invoice extraction across thousands of diverse vendor formats.
The model’s speed and efficiency allowed us to process high-volume invoice queues while reducing per-document compute costs by 70% compared to Claude.
For any team building an invoice scanning software or designing pipelines for OCR invoice scanning, Gemini 2.5 Flash offers an excellent balance of speed, cost, and quality.

Combined with a strong prompt-engineering strategy, it’s a powerful foundation for reliable, context-aware data pipelines.
But getting here wasn't straightforward. Every production system has its rough edges, and ours was no exception.
Challenges We Faced Along the Way
Building a production-grade invoice scanning system wasn't without its bumps. Here are some of the technical challenges we encountered and had to work around:
Context Window Limitations (Tier-Based Rate Limits)
When we first started with Claude 3.7, we hit tier-based rate limits faster than expected. The 64k token context window was impressive, but processing high volumes of multi-page invoices meant we'd quickly exhaust our quota during peak hours. For teams running bulk processing queues, these rate limits can become a real bottleneck. We had to implement smarter batching strategies and eventually moved to Gemini, which offered more predictable throughput for our use case.
Timeout Issues During Model Inference
LLMs aren't instant. When dealing with extended reasoning chains (especially with thinking models), we occasionally hit timeout errors during API calls. A single complex invoice with nested tables and multi-page structures could take 3 to 5 seconds to process. For real-time workflows, this latency adds up. We solved this by implementing asynchronous processing with proper retry logic and fallback mechanisms to handle transient failures gracefully.
Partial JSON Generation in LLM Outputs
This one was frustrating. Even with strict schema definitions, LLMs would occasionally return incomplete or malformed JSON: missing closing brackets, truncated arrays, or partially generated line items. It happened more often on longer invoices where the model would hit token limits mid-generation. We addressed this by enforcing stricter schema validation using Zod, adding thorough error handling, and breaking down complex extraction tasks into smaller, more manageable prompts.
API Costs at Scale
Running LLM inference on thousands of invoices daily isn't cheap. Claude's per-token pricing, while reasonable for prototyping, became expensive at production scale. Each invoice scan could cost $0.05 to $0.10 depending on length and complexity. Switching to Gemini 2.5 Flash reduced our per-document cost by roughly 70%, making the economics work for high-volume automation. But cost optimization remains an ongoing consideration, especially when balancing accuracy with budget constraints.
None of these issues were dealbreakers, but they're the kind of real-world friction that doesn't show up in vendor demos or model benchmarks. Sharing them openly helps other teams avoid the same pitfalls and sets realistic expectations for what it takes to ship production-ready AI systems.
Building reliable automation isn't just about choosing the best model. It's about engineering around the sharp edges and designing systems that gracefully handle failures, scale under load, and stay within budget.
Despite these hurdles, the system we built delivered results that exceeded our initial expectations.
Results and Lessons Learned
Looking back, combining OCR invoice scanning with Large Language Models felt like moving from static maps to a fully interactive GPS system.
The shift transformed a brittle, template-driven process into a dynamic pipeline capable of adapting to any vendor layout and handling high volumes with ease.
Accuracy: Line-item recall improved dramatically, rising from 88% with OCR and regex-based extraction to 97% with OCR combined with LLMs. This uplift made the pipeline reliable enough for direct integration with downstream finance systems.
Scalability: Gemini’s 65k token context window enabled us to process large, multi-page telecom invoices without the need for aggressive document chunking. This eliminated complexity in pre-processing and reduced edge-case errors during invoice data extraction.
Cost Efficiency: Migrating to Gemini 2.5 Flash reduced per-document compute costs by approximately 70% compared to Claude. This cost-performance balance made the solution viable for high-volume scenarios like enterprise billing systems or large-scale AI invoice extraction workflows.
Along the way, we uncovered some important engineering insights:
Schema Enforcement: Defining strict JSON schemas using Zod proved essential. It ensured that the output from the LLM consistently adhered to the required structure, eliminating the need for costly post-processing and reducing API error rates.
Prompt Tuning: Achieving production-grade consistency required iterative refinement of prompts. Simple changes such as explicitly instructing the model to preserve the original line-item order, saved hours of downstream QA and debugging.
Hybrid Approach: LLMs work best as part of a broader toolchain. When paired with classic OCR engines and external APIs, they deliver the reasoning and flexibility that traditional systems lack. This hybrid strategy is the key to successfully automate invoice extraction without sacrificing accuracy or speed.
By combining the strengths of OCR and LLMs, we were able to create a system capable of handling real-world document variability while delivering clean, structured outputs ready for ingestion into financial and operational systems.
Closing Thoughts
Invoice processing has always felt like a battle against edge cases. Vendor-specific templates, inconsistent layouts, and unpredictable data structures often pushed teams like ours into building fragile systems full of hardcoded rules and endless patchwork fixes.
Bringing LLMs into the workflow changed everything for us.
We created a pipeline that’s not just faster but also far more resilient and adaptable to diverse vendor formats.
The system blends OCR invoice scanning for precise text extraction with the reasoning power of LLMs to understand context, relationships, and even complex business rules.
If you’re exploring similar solutions, here’s what we’ve learned: don’t try to replace OCR entirely, augment it. Let OCR handle raw text extraction efficiently, then use LLMs for mapping fields, managing layout variability, and applying domain-specific logic.
This hybrid strategy is what makes enterprise-grade invoice data extraction scalable and reliable. It’s also the key to automate invoice extraction workflows without introducing unnecessary complexity or skyrocketing costs.
We truly believe the future of AI invoice extraction lies in combining traditional tools with modern AI models to deliver structured, schema-perfect data that’s ready for operational systems.
Thinking of building something similar?
Or exploring how LLMs could fit into your workflow?
Let’s build it together. Reach out, we’d love to explore what’s possible for your use case.
Ask an AI
Get an instant summary of this post from your preferred AI assistant.
Frequently asked questions
- Traditional OCR can convert scanned text but struggles with understanding complex layouts, variable formats, and context. LLMs add intelligence, allowing automated invoice scanning systems to extract structured data accurately across diverse vendor templates.
- Here’s a concise list of benefits of using LLMs for invoice data extraction: Understands context and relationships between fields (e.g., vendor ↔ totals ↔ line items) Adapts to diverse invoice formats without fixed templates Handles imperfect scans and noisy data better than traditional OCR Outputs clean, structured JSON ready for downstream systems Reduces manual intervention and improves scalability Learns complex business rules (e.g., skip taxes on fuel invoices) Speeds up processing while maintaining high accuracy
- We use OCR to extract raw text when needed and layer LLMs for reasoning, cleaning, and structuring data. This hybrid approach delivers speed, adaptability, and high accuracy for automated invoice scanning workflows.
- Gemini 2.5 Flash proved to be the most effective in our tests, balancing extraction quality, scalability, and cost. Models with large token windows are essential for processing multi-page invoices without splitting context.
- Yes. The same AI techniques used for invoice scanning can be adapted for contracts, receipts, and other semi-structured documents where context and accuracy are critical.
Related articles

How to Build a Marketplace App: Cost, Build Phases, and When Not to Use Sharetribe
A practical guide for founders building two-sided marketplace apps in specific verticals. Covers cost ranges, V1/V2/V3 feature phasing, the Sharetribe vs. custom decision, and the supply problem that kills most marketplace launches.

How to Build a Healthcare App : The Ultimate Guide
A practical guide to building a healthcare app. Covers features, tech stack, regulatory requirements, team structure, and development cost, with examples from leading platforms.

Medspa Management Software: Build vs. Buy for Multi-Location Chains (2026)
Aesthetic Record costs up to $699/month per location. A 15-location chain pays over $125,000 a year for software that still cannot sync loyalty points across sites or generate a single roll-up P&L. Here is when custom medspa management software makes financial sense, what it costs, and what the first 90 days look like.